

Imagen 1. (Principio básico de la cámara lúcida, un dispositivo óptico de dibujo ampliamente utilizado por artistas y estudiantes del arte en el siglo XIX. Fuente: https://neolucida.com/history
Parece que estamos en el inicio de una verdadera revolución en la creación de medios: el auge de los medios generativos.[1][2] He utilizado herramientas informáticas para el arte y el diseño desde 1984, y he presenciado algunas revoluciones mediáticas importantes, como la introducción de las computadoras Mac y las aplicaciones de escritorio para la creación y edición de medios, el desarrollo de gráficos y animación 3D fotorrealistas por computadora, el auge de la web después de 1993 y el auge de las redes sociales después de 2006. La nueva revolución de los medios generativos con IA parece ser tan significativa como cualquiera de ellas. De hecho, es posible que sea tan significativa como la invención de la fotografía en el siglo XIX o la adopción de la perspectiva lineal en el arte occidental en el siglo XVI.
(Si eres nuevo en este tema, aquí tienes una breve historia. La revolución de los medios generativos estuvo en desarrollo durante más de 20 años. Los primeros artículos sobre IA que proponían que el vasto universo web no estructurado de textos, imágenes y otros artefactos culturales se pudiera utilizar para entrenar a las computadoras a realizar diversas tareas aparecieron ya en 1999-2001. En 2015, los métodos de “sueño profundo” y “transferencia de estilo” de Google atrajeron mucha atención: de repente, las computadoras podían crear nuevas imágenes artísticas que imitaban los estilos de muchos artistas famosos. El lanzamiento de DALL-E en enero de 2021 fue otro hito: ahora las computadoras podían sintetizar imágenes a partir de la descripción del texto. Midjourney, Stable Diffusion y DALL-E 2 contribuyeron a la aceleración de esta evolución en 2022. Ahora las imágenes sintéticas podían tener muchas estéticas que van desde el fotorrealismo hasta cualquier tipo de medio físico o digital, incluidos mosaicos, pinturas al óleo, fotografía callejera o renderizado 3D CG. El código para producir dichas imágenes, conocido como “modelo” en el campo de la inteligencia artificial, se sacó a la luz en agosto de 2022, lo que desencadenó una oleada de experimentos y aceleró el desarrollo).
En este capítulo y en los siguientes, describiré varias características de los medios generativos visuales en sus formas actuales que considero particularmente significativas o novedosas. Algunos de mis argumentos también se aplican a los medios generativos en general, pero la mayoría se centra en los medios visuales, lo que refleja mi propia experiencia con el uso diario de algunas herramientas populares de IA para imágenes, como Midjourney y Stable Diffusion (e incluso, también Runway ML), desde mediados de 2022 hasta principios de 2023. Pero primero, definamos los términos principales.
Los términos
En este texto, “artista” o “creador” se refiere a cualquier persona cualificada que crea objetos culturales en cualquier medio o combinación de estos. Los términos “medios generativos,” “medios de IA,” “IA generativa” y “medios sintéticos” son intercambiables. Se refieren al proceso de creación de nuevos objetos multimedia mediante redes neuronales profundas, como imágenes, animación, vídeo, texto, música, modelos y escenas 3D, y otros tipos de medios. Las redes neuronales también se utilizan para generar elementos y tipos de contenido específicos, como rostros humanos fotorrealistas, poses y movimientos humanos, además de tales objetos. También se pueden utilizar en la edición multimedia, por ejemplo, para reemplazar una parte de una imagen o vídeo con otro contenido que se ajuste al espacio.
Estas redes se entrenan con vastas colecciones de objetos multimedia ya existentes. Los tipos más populares de redes neuronales artificiales para la generación de medios incluyen los modelos de difusión, los modelos de texto a imagen, las redes generativas antagónicas (GAN) y los transformadores. Para la generación de imágenes fijas y en movimiento mediante redes neuronales, los términos generación de imágenes, imagen sintética, imagen de IA y visuales de IA pueden usarse indistintamente.
Cabe destacar que el término “generativo” también puede usarse de diferentes maneras para referirse a la creación de artefactos culturales mediante cualquier proceso algorítmico (en lugar de solo redes neuronales) o incluso un proceso basado en reglas que no utiliza computadoras. Así es como se suelen usar hoy en día los términos “arte generativo” y “diseño generativo” en los discursos culturales y los medios de comunicación populares. En este capítulo, utilizo “generativo” de forma más restrictiva para designar los métodos de redes profundas y las aplicaciones para la generación de medios que utilizan estos métodos.
- La ‘IA’ como percepción cultural
No existe una tecnología específica ni un solo proyecto de investigación denominado ‘IA.’ Sin embargo, podemos observar cómo evolucionó nuestra percepción cultural de este concepto a lo largo del tiempo y a qué se refería en cada período. En los últimos cincuenta años, cuando una capacidad o habilidad exclusivamente humana, supuestamente, se automatiza mediante tecnología informática, la denominamos ‘IA.’ Sin embargo, en cuanto esta automatización se realiza de forma fluida y completa, tendemos a dejar de referirnos a ella como un ‘caso de IA.’ En otras palabras, ´IA’ se refiere a las tecnologías y las metodologías que automatizan las capacidades cognitivas humanas y que están empezando a funcionar pero aún no han llegado a su fin. La ‘IA’ ya estaba presente en las primeras herramientas informáticas. El primer sistema interactivo de dibujo y diseño, Sketchpad de Ivan Sutherland (1961-1962), contaba con una función que podía finalizar de manera automática cualquier rectángulo o círculo que se empezara a dibujar. En otras palabras, sabía lo que se intentaba crear. En el sentido amplio que acabamos de dar, esto ya era, sin duda, ‘IA.’
Mi primera experiencia con un programa de dibujo de escritorio en una Apple II fue en 1984, y fue realmente asombroso mover el ratón y ver aparecer pinceladas simuladas en la pantalla. Sin embargo, hoy en día ya no consideramos esto ‘IA.’ Otro ejemplo sería la función de Photoshop que selecciona automáticamente el contorno de un objeto. Esta función se añadió hace muchos años; también es ‘IA’ en sentido amplio, pero hoy en día nadie se referiría a ella como tal. La historia de los sistemas y herramientas de medios digitales está llena de estos ‘momentos de IA’: sorprendentes al principio, luego dados por sentado y olvidados como ‘IA’ con el tiempo. (En los libros de historia de la IA, este fenómeno se conoce como el ‘efecto IA.’) Actualmente, la ‘IA creativa’ se refiere únicamente a métodos desarrollados recientemente donde las computadoras transforman algunas entradas en nuevos productos mediáticos (por ejemplo, modelos de texto a imagen) y técnicas específicas (por ejemplo, ciertos tipos de redes neuronales profundas). Sin embargo, debemos recordar que estos métodos no son los primeros ni los últimos en la larga historia y el futuro de la simulación de las habilidades artísticas humanas o la asistencia a las personas en la creación de medios.
- “Hazlo Nuevo”: IA y el modernismo
Tras el entrenamiento con billones de páginas de texto o miles de millones de imágenes artísticas y fotográficas extraídas de la web, las redes neuronales pueden generar textos e imágenes novedosos al nivel de escritores, artistas, fotógrafos o ilustradores profesionales altamente competentes. Estas capacidades de las redes de sistemas de IA se distribuyen en billones de conexiones entre miles de millones de neuronas artificiales, en lugar de estar determinadas por algoritmos estándar. En otras palabras, desarrollamos una tecnología que, en términos de complejidad, es extremadamente similar a la del cerebro humano. No comprendemos completamente cómo funciona nuestra tecnología de IA, al igual que no comprendemos completamente el intelecto y la creatividad humana.
La generación actual de sistemas de IA generativa, como GPT y Stable Diffusion, se ha estado entrenando con conjuntos de datos muy grandes y diversos que consisten en miles de millones o incluso billones de textos individuales, o pares de imágenes y textos. Sin embargo, es igualmente interesante limitar el conjunto de datos de entrenamiento a un área específica dentro del espacio más amplio de la historia cultural humana, o a un conjunto específico de artistas de un período histórico específico. Unsupervised (https://refikanadol.com/works/unsupervised/) de Refik Anadol Studio (2022) es un proyecto artístico de IA que ejemplifica estas posibilidades. El proyecto utiliza redes neuronales entrenadas con el conjunto de datos de imágenes de decenas de miles de obras de arte de la colección del MoMA. Esta colección, en mi opinión, es una de las mejores representaciones del período más creativo y experimental de la historia visual de la humanidad —cien años de arte moderno (1870-1970)—, así como numerosos ejemplos importantes de las exploraciones artísticas de las décadas posteriores. Captura los experimentos febriles e incesantes de los artistas modernistas para crear nuevos lenguajes visuales y de comunicación y “renovarlos.”

Imagen 2. https://refikanadol.com/works/unsupervised/ fotogramas seleccionados de la animación.
A primera vista, la lógica del modernismo parece diametralmente opuesta al proceso de entrenamiento de sistemas de IA generativa. Los artistas modernos deseaban distanciarse del arte clásico y sus características definitorias, como la simetría visual, las composiciones jerárquicas y el contenido narrativo. En otras palabras, su arte se basaba en un rechazo fundamental de todo lo anterior (al menos en teoría, como se expresa en sus manifiestos). Las redes neuronales se entrenan de forma opuesta, aprendiendo de la cultura histórica y del arte creado hasta la fecha. Una red neuronal es análoga a un artista muy conservador que estudia en el “meta” “museo sin paredes” que alberga el arte histórico.
Pero todos sabemos que la teoría del arte y la práctica artística no son lo mismo. Los artistas modernos no rechazaron por completo el pasado ni todo lo que les precedió. En cambio, el arte moderno se desarrolló reinterpretando y copiando imágenes y formas de antiguas tradiciones artísticas, como los grabados japoneses (Van Gogh), la escultura africana (Picasso) y los iconos rusos (Malevich). Así, los artistas solo rechazaron los paradigmas artísticos dominantes de la época, el arte realista y el arte de salón, pero no el resto de la historia del arte. En otras palabras, fue profundamente historicista: en lugar de inventarlo todo desde cero, innovó adaptando ciertas estéticas antiguas a los contextos del arte contemporáneo. (En el caso del arte abstracto geométrico creado en la década de 1910, estos artistas emplearon imágenes que ya eran ampliamente utilizadas en psicología experimental para estudiar la percepción y la sensación visual humana. Para un análisis detallado de estas relaciones entre el arte moderno y la psicología experimental, véase Paul Vitz y Arnold Glimcher, Modern art and Modern Science: The Parallel Analysis of Vision, 1983 (https://www.researchgate.net/profile/Paul-Vitz/publication/322769258_Modern_Art_and_Modern_Science_The_Parallel_Analysis_of_Vision/links/5a6f5ffa0f7e9ba2e1c87e7e/Modern-Art-and-Modern-Science-The-Parallel-Analysis-of-Vision.pdf) .
En lo que respecta a la IA artística, no debemos dejarnos cegar por cómo se entrenan estos sistemas. Sí, las redes neuronales artificiales se entrenan con artefactos artísticos y culturales humanos previamente creados. Sin embargo, sus nuevos resultados no son réplicas mecánicas ni simulaciones de lo ya creado. En mi opinión, con frecuencia se trata de artefactos culturales genuinamente nuevos con contenido, estética o estilos inéditos.
Por supuesto, el simple hecho de ser novedoso no implica automáticamente que algo sea interesante o significativo desde el punto de vista cultural o social. De hecho, muchas definiciones de “creatividad” coinciden en este punto: es la creación de algo lo que lo hace original, valioso o útil.
Sin embargo, estimar qué porcentaje de todos los artefactos novedosos producidos por IA generativa también son útiles o significativos para una cultura más amplia no es un proyecto viable en este momento. Para empezar, no conozco ningún esfuerzo sistemático para utilizar dichos sistemas para “rellenar,” por así decirlo, una matriz masiva de todo el contenido y las posibilidades estéticas mediante la provisión de millones de indicaciones específicamente diseñadas. En cambio, es probable que, como en cualquier otra área de la cultura popular, solo un pequeño número de posibilidades se realicen una y otra vez por millones de usuarios, dejando una larga lista de otras posibilidades sin realizar. Por lo tanto, si solo una pequeña fracción del vasto universo de posibles artefactos de IA se realiza en la práctica, no podemos hacer afirmaciones generales sobre la originalidad o utilidad del resto del universo.
- Medios generativos y arte de bases de datos
Algunos artistas de IA como Anna Ridler http://annaridler.com,) Sarah Meyohas (https://aiartists.org/sarah-meyohas) y Refik Anadol (https://refikanadol.com) utilizaron en sus trabajos redes neuronales entrenadas con conjuntos de datos específicos. Muchos otros artistas, diseñadores, arquitectos y tecnólogos utilizan redes neuronales publicadas por otras empresas o instituciones de investigación, ya entrenadas con conjuntos de datos muy grandes (p. ej., Difusión Estable), y luego las perfeccionan con sus propios datos.
Por ejemplo, el artista Lev Pereulkov perfeccionó el modelo de Difusión Estable 2.1 utilizando 40 pinturas de reconocidos artistas “inconformistas” que trabajaron en la URSS a partir de la década de 1960 (Erik Bulatov, Ilya Kabakov, etc.). La serie de imágenes de Pereulkov, Experimentos Artificiales 1–10 (2023), creada con esta red personalizada, es una obra de arte original que captura las características artísticas de estos artistas, así como su singular semántica surrealista y absurda, sin repetir de forma exacta ninguna de sus obras existentes. En cambio, sus “ADN,” capturados por la red, permiten nuevos significados y conceptos visuales.

Imagen 3. (Lev Pereulkov, Artifical Experiments 1–10, 2022. Tres imágenes de la serie de 10 compartidas en Instagram.
La mayoría de los millones de personas comunes y profesionales creativos que emplean herramientas de medios generativos las usan tal cual, sin perfeccionarlas. Esto podría cambiar en el futuro, a medida que las redes técnicas que utilizan nuestros propios datos se vuelvan más fáciles de usar. Pero independientemente de estas particularidades, todos los artefactos culturales recién creados por redes entrenadas tienen una lógica común.
A diferencia de los dibujos, esculturas y pinturas tradicionales, los artefactos de medios generativos no se crean desde cero. Tampoco son el resultado de capturar algún tipo de fenómeno sensorial, como fotos, videos o grabaciones de sonido. En cambio, se construyen a partir de Un amplio archivo de otros artefactos mediáticos. Este mecanismo generativo vincula los medios generativos con géneros y procesos artísticos anteriores.
Podemos compararlo con la edición cinematográfica, que apareció por primera vez alrededor de 1898, o incluso con la fotografía compuesta, popular en el siglo XIX. También podemos considerar obras de arte específicas que son especialmente relevantes, como la película de collage experimental A Movie (https://en.wikipedia.org/wiki/A_Movie Bruce Conner, 1958) o muchas instalaciones de Nam June Park que presentan fragmentos editados de secuencias de televisión.
Viendo proyectos como Unsupervised o Artifical Experiments 1-10 en el contexto de este método de creación de medios y sus variaciones históricas nos ayudará a comprender esta y muchas otras obras de IA como objetos de arte que dialogan con el arte del pasado, más que como novedades puramente tecnológicas u obras de entretenimiento.
Veo muchos momentos y períodos relevantes cuando examino la historia del arte, la cultura visual y los medios en busca de otros usos destacados de este procedimiento. Son relevantes para los medios generativos actuales no solo porque los artistas de la época utilizaban el procedimiento, sino también porque la razón de este uso era constante en todos los casos. Una nueva acumulación y accesibilidad de grandes cantidades de artefactos culturales llevó a los artistas a crear nuevas formas de arte a partir de estas acumulaciones. Permítanme describir algunos de estos ejemplos.
Artistas de internet y digitales crearon diversas obras a finales de la década de 1990 y principios de la década de 2000 en respuesta al nuevo y creciente universo de la web. _readme (1998) de Health Bunting (http://www.medienkunstnetz.de/works/readme/,) por ejemplo, es una página web que contiene el texto de un artículo sobre el artista, con cada palabra enlazada a un dominio web existente correspondiente a esa palabra. Shredder 1.0 https://en.wikipedia.org/wiki/Shredder_1.0
(también de 1998) de Mark Napier presenta un montaje dinámico de elementos que comprenden numerosos sitios web: imágenes, textos, código HTML y enlaces.
Retrocediendo en el tiempo, encontramos un amplio paradigma cultural que también fue una reacción a la acumulación de artefactos históricos de arte y cultura en colecciones de medios de fácil acceso. Este paradigma se conoce como “posmodernismo.” Los artistas y diseñadores posmodernos recurrían con frecuencia al bricolaje y creaban obras compuestas por citas y referencias al arte del pasado, rechazando el enfoque del modernismo en la novedad y rompiendo con el pasado.
Si bien existen muchas explicaciones posibles para el surgimiento del paradigma posmoderno en las décadas de 1960 y 1980, una es relevante para nuestro análisis. La acumulación de artefactos artísticos y mediáticos anteriores en colecciones estructuradas y accesibles, como bibliotecas de diapositivas, archivos cinematográficos, libros de texto de historia del arte con numerosas fotos de las obras y otros formatos —donde se combinaban diferentes períodos históricos, movimientos y creadores— inspiró a los artistas a crear bricolajes a partir de dichas referencias, además de citarlas extensamente.

Imagen 4. (Fotomontaje de John Heartfield, 1919.)
¿Qué ocurrió con el “modernismo” en las décadas de 1910 y 1920? Si bien el énfasis general recaía en la originalidad y la novedad, uno de los procedimientos que desarrolló en busca de la novedad fueron las citas directas del vasto universo de los medios visuales contemporáneos, que se expandía rápidamente en aquel momento. Los grandes titulares, por ejemplo, y la inclusión de fotos y mapas hicieron que los periódicos tuvieran un mayor impacto visual; también se lanzaron nuevas revistas de orientación visual, como Vogue y Times, en 1913 y 1923, respectivamente; y, por supuesto, el cine, un nuevo medio, continuó desarrollándose.
En respuesta a esta intensificación visual de la cultura de masas, a principios de la década de 1910, Georges Braque y Pablo Picasso comenzaron a incorporar fragmentos reales de periódicos, carteles, papel pintado y tela en sus pinturas. Unos años más tarde, John Heartfield, George Grosz, Hannah Hoch, Aleksandr Rodchenko y otros artistas comenzaron a desarrollar técnicas de fotocollage. El fotocollage se convirtió en otro método para crear nuevos artefactos mediáticos a partir de imágenes existentes de los medios de comunicación.
Las obras de arte contemporáneas que emplean redes neuronales entrenadas en bases de datos culturales, como Unsupervised or Artificial Experiments 1-10, continúan una larga tradición de creación de arte nuevo a partir de acumulaciones de imágenes y otros medios. De esta manera, estas obras de arte abren nuevas posibilidades para el arte y sus técnicas, en particular las que denominé anteriormente “database art” (véase mi artículo “Database as a Symbolic Form,” 1998 https://manovich.net/index.php/projects/database-as-a-symbolic-form). La introducción de nuevos métodos para leer bases de datos culturales y crear nuevas narrativas a partir de ellas forma parte de esta expansión.
Por lo tanto, Unsupervised no crea collages a partir de imágenes existentes, como hacían los artistas modernistas de la década de 1920, ni las cita extensamente, como hacían los artistas posmodernos de la década de 1980. En cambio, el grupo entrena una red neuronal para extraer patrones de decenas de miles de obras de arte del MoMA. La red entrenada genera entonces nuevas imágenes que comparten los mismos patrones, pero que no se parecen a ninguna pintura específica. A lo largo de la animación, recorremos el espacio de estos patrones (por ejemplo, el “espacio latente,”) explorando diversas regiones del universo del arte contemporáneo. (Para más detalles sobre los métodos de entrenamiento de redes GAN utilizados por Refik Anadol Studio, véase “Creating Art with Generative Adversarial Network: Refik Anadol’s Walt Disney Concert Hall Dreams,” 2022
Artificial Experiments 1-10 de Pereulkov utilizan una técnica diferente para generar nuevas imágenes a partir de una base de datos de imágenes existente. Seleccionó solo cuarenta pinturas de artistas que comparten características clave. Desarrollaron su arte de oposición en la sociedad comunista tardía (URSS, décadas de 1960-1980). También vivieron en la misma cultura visual. En mis recuerdos, esta sociedad estaba dominada por dos colores: el gris (que representa la monotonía de la vida urbana) y el rojo de la propaganda.
Además, Pereulkov eligió pinturas que comparten algo más: “Por lo general, elegía pinturas que se relacionanan conceptualmente de alguna manera con el lienzo, o con el espacio que lo recubre. Obtuve la pintura New Accordion de Kabakov, que presenta aplicaciones de papel sobre el lienzo” (mi comunicación personal con Pereulkov, 16/04/2023.) Pereulkov también elaboró descripciones de texto personalizadas para cada pintura utilizadas para afinar el modelo de la Difusión Estable. Para enseñar al modelo los lenguajes visuales específicos de los artistas seleccionados, añadió términos como “trazos gruesos,” “iluminación roja,” “fondo azul” y “círculos planos” a estas descripciones.
Claramente, cada uno de estos pasos representa una decisión conceptual y estética. En otras palabras, la clave del éxito de Artificial Experiments 1-10 reside en la creación de dicha base de datos. Este trabajo demuestra cómo el ajuste de una red neuronal existente, entrenada con miles de millones de pares de imágenes y textos (como Difusión Estable), puede lograr que esta red siga las ideas de los artistas; los sesgos y el ruido de una red tan masiva pueden superarse y minimizarse, y no necesitan dominar nuestra imaginación.
- De la Representación a la Predicción
Históricamente, los humanos creaban imágenes de escenas existentes o imaginarias mediante diversos métodos, desde el dibujo manual hasta la animación por computadora en 3D (véase más adelante la explicación de los métodos). Con los medios generativos de IA, surge un método fundamentalmente nuevo. Las computadoras utilizan grandes conjuntos de datos de representaciones existentes en diversos medios para predecir nuevas imágenes (fijas y animadas).
Ciertamente, se pueden proponer diferentes trayectorias históricas que conducen a los medios visuales generativos actuales, o dividir una línea de tiempo histórica en diferentes etapas. He aquí una posible trayectoria:
- Creación manual de representaciones (p. ej., dibujo con diversos instrumentos, tallado, etc.). Las etapas y partes más mecánicas eran a veces realizadas por asistentes humanos que generalmente se formaban en el taller de su profesor, por lo que ya existe cierta delegación de funciones.
- Creación manual, pero utilizando dispositivos de asistencia (p. ej., máquinas de perspectiva, cámara lúcida). De mano a mano + dispositivo. Ahora algunas funciones se delegan a dispositivos mecánicos y ópticos.
- Fotografía, rayos X, vídeo, captura volumétrica, teledetección, fotogrametría. Desde el uso de las manos al registro de información mediante máquinas. De asistentes humanos a asistentes mecánicos.
- CG 3D. Defines un modelo 3D en una computadora y utilizas algoritmos que simulan efectos de fuentes de luz, sombras, niebla, transparencia, translucidez, texturas naturales, profundidad de campo, desenfoque de movimiento, etc. De la grabación a la simulación.
- IA generativa. Uso de conjuntos de datos multimedia para predecir imágenes fijas y en movimiento. De la simulación a la predicción.
La “predicción” es el término que suelen utilizar los investigadores de IA en sus publicaciones que describen métodos de medios visuales generativos. Si bien este término puede usarse de forma figurativa y evocativa, esto es también lo que ocurre científicamente al utilizar herramientas generativas de imágenes. Al trabajar con un modelo de IA de texto a imagen, la red neuronal intenta predecir las imágenes que corresponden mejor al texto introducido. Con esto no estoy sugeriendo que el uso de otros términos ya aceptados, como “medios generativos,” sea inapropiado. Pero si queremos comprender mejor la diferencia entre los métodos de síntesis de medios visuales de IA y otros métodos de representación desarrollados a lo largo de la historia, emplear el concepto de “predicción” y, por lo tanto, referirse a estos sistemas de IA como “medios predictivos” refleja bien esta diferencia.
- Traducciones de medios
Existen varios métodos para crear “medios de IA.” Un método transforma la información de los medios humanos conservando el mismo tipo de medio. El texto introducido por el usuario, por ejemplo, puede resumirse, reescribirse, ampliarse, etc. La salida, al igual que la entrada, es un texto. Como alternativa, en el método de generación de imagen a imagen, se utilizan una o más imágenes de entrada para generar nuevas imágenes.
Sin embargo, existe otra vía igualmente intrigante desde las perspectivas histórica y teórica. Los “medios de IA” pueden crearse “traduciendo” automáticamente el contenido entre diferentes tipos de medios. Esto es lo que ocurre, por ejemplo, cuando se utiliza Midjoiurney, Stable Diffusion u otro servicio de generación de imágenes de IA y se introduce un mensaje de texto, la IA genera una o más imágenes como respuesta. El texto se “traduce” a una imagen.
Dado que no se trata de una traducción literal, pongo la palabra ‘traducción’ entre comillas. En cambio, la entrada de un medio indica a una red neuronal que prediga la salida apropiada de otro. También puede decirse que dicha entrada queda ‘mapeada’ a ciertas salidas en otros medios. El texto se mapea a nuevos estilos de texto, imágenes, animación, vídeo, modelos 3D y música. El vídeo se convierte en modelos 3D o animación. Las imágenes se traducen a texto, y así sucesivamente. El método de traducción de texto a imagen es actualmente más avanzado que otros, pero con el tiempo se irá actualizando.
La traducción (o mapeo) entre medios no es un concepto nuevo. Estas traducciones se han realizado manualmente a lo largo de la historia de la humanidad, a menudo con una intención artística. Se han adaptado novelas al teatro y al cine, cómics a series de televisión, textos de ficción o no ficción se han ilustrado con imágenes, etc. Cada una de estas traducciones fue un acto cultural deliberado que requería habilidades profesionales y el conocimiento de los medios adecuados. Algunas de estas traducciones ahora pueden realizarse automáticamente a gran escala gracias a las redes neuronales artificiales, convirtiéndose en un nuevo medio de comunicación y creación cultural. Claro que la adaptación artística de una novela al cine por parte de un equipo humano y la generación automática de imágenes a partir del texto de la novela por una red no son lo mismo, pero en muchos casos más sencillos la traducción automática de medios puede funcionar bien. Lo que antes era un acto artístico especializado es ahora una capacidad tecnológica al alcance de todos. Podemos lamentarnos por todo lo que podría perderse como resultado de la automatización —y democratización— de esta crucial operación cultural: habilidades, algo que podríamos llamar “profunda originalidad artística” o “profunda creatividad,” etc. Sin embargo, dicha pérdida podría ser solo temporal si, por ejemplo, se mejoran aún más las capacidades de la ‘IA cultural’ para generar más contenido original y comprender mejor el contexto.
Dado que la mayoría de las personas en nuestra sociedad pueden leer y escribir en al menos un idioma, los métodos de conversión de un texto a otro son actualmente los más populares. Incluyen modelos de texto a imagen, texto a animación, texto a 3D y texto a música. Estas herramientas de IA pueden ser utilizadas por cualquier persona que sepa escribir, o mediante un software de traducción disponible inmediatamente para crear un mensaje en cualquiera de los idiomas que estas herramientas comprendan mejor en un momento dado. Sin embargo, otras asignaciones de medios pueden ser igualmente interesantes para los creadores profesionales. A lo largo de la historia cultural de la humanidad, diversas traducciones entre tipos de medios han llamado la atención. Incluyen traducciones entre vídeo y música realizadas por VJ en clubes; largas narrativas literarias convertidas en películas y series de televisión; textos ilustrados con imágenes en diversos medios, como grabados; números convertidos en imágenes (arte digital); textos que describen pinturas (tradición de la ekphrasis, que comenzó en la antigua Grecia), mapeos entre sonidos y colores (especialmente populares en el arte modernista); etc.
El desarrollo continuo de modelos de IA para mapeos entre todo tipo de medios, sin privilegiar el texto, tiene el potencial de ser extremadamente fructífero, y espero que más herramientas puedan lograrlo. Dichas herramientas serán muy útiles tanto para artistas profesionales como para otros creadores. Sin embargo, como artista, no afirmo que la futura “IA cultural” pueda igualar, por ejemplo, las innovadoras interpretaciones de Hamlet por directores de teatro vanguardistas como Peter Brook o las asombrosas películas de Oscar Fishinger que exploraron las correspondencias musicales y visuales. Basta con que las nuevas herramientas de IA para mapeo de medios estimulen nuestra imaginación, nos brinden nuevas ideas y nos permitan explorar numerosas variaciones de diseños específicos.
- Lo estereotipado y lo único
Tanto el proceso de creación humana moderna como el proceso de medios generativos de IA predictiva parecen funcionar de manera similar. Una red neuronal se entrena utilizando colecciones no estructuradas de contenido cultural, como miles de millones de imágenes y sus descripciones o billones de páginas web y de libros. La red neuronal aprende asociaciones entre los componentes de estos artefactos (como qué palabras aparecen frecuentemente una junto a otra), así como sus patrones y estructuras comunes. La red entrenada utiliza estas estructuras, patrones y ‘átomos culturales’ para crear nuevos artefactos cuando se lo solicitamos. Dependiendo de lo que pidamos, estos artefactos creados por IA pueden parecerse mucho a lo que ya existe o no.
De manera similar, nuestra vida es un proceso continuo de entrenamiento cultural, tanto supervisado como no supervisado. Tomamos cursos de arte e historia del arte, consultamos sitios web, vídeos, revistas y catálogos de exposiciones, visitamos museos y viajamos para absorber nueva información cultural. Y cuando nos ‘animamos’ para crear nuevos artefactos culturales, nuestras propias redes neuronales biológicas (infinitamente más complejas que cualquier red de IA hasta la fecha) generan dichos artefactos basándose en lo que hemos aprendido hasta el momento: patrones generales observados, plantillas para crear objetos específicos y, a menudo, partes concretas de artefactos existentes. En otras palabras, nuestras creaciones pueden contener tanto réplicas exactas de artefactos previamente observados como elementos nuevos que representamos utilizando plantillas aprendidas, como la proporción áurea o el uso de colores complementarios.
Las redes neuronales de IA utilizadas para la generación de imágenes suelen tener un estilo de “casa” predeterminado. Este es el término que utilizan los desarrolladores de MidJourney. Si no se especifica un estilo explícitamente, la IA lo generará utilizando esta estética “por defecto.”

Imagen 5. (Ejemplos generados en Midjourney versión 4 utilizando el prompt del texto “cielo matutino”.)
Para evitar este defecto, necesitas añadir ciertos términos a tus indicaciones que especifiquen una descripción del medio, el tipo de iluminación, los colores y el sombreado, o una frase como “al estilo de” seguida del nombre de un artista, ilustrador, fotógrafo, diseñador de moda o arquitecto reconocido. Aquí tienes dos ejemplos de indicaciones que creé y las imágenes que Midjourney generó a partir de ellas. Los términos utilizados para definir características de estilo específicas están resaltados.

Prompt 1:
“Gigante aeropuerto moderno del futuro de 1965 en Siberia, hecho de agua y hielo, pintado sobre un gran panel de madera por El Bosco, brillantes colores pastel con reflejos blancos, lente 23f, muy detallado –ar 4:3 –s 1250 —prueba”
(Imagen generada con Midjourney v3)

Prompt 2:
“Foto de dos estudiantes de secundaria rusos, piel clara, luz de estudio muy suave, lente de 50 mm, monocromática, tonos plateados, alta calidad, ultrarrealista –v 4 –q 2”
(Imagen generada con Midjourney v4)
Esta imagen también ilustra el punto que abordaré más adelante en el capítulo: “La IA genera con frecuencia nuevos artefactos multimedia que son más estereotipados o idealizados de lo que pretendíamos.”
Dado que puede simular miles de estéticas y estilos ya existentes e interpolarlos para crear nuevos híbridos, la IA es más capaz que cualquier creador humano en este aspecto. Sin embargo, actualmente, los creadores humanos cualificados y con amplia experiencia también cuentan con una ventaja significativa. Tanto los humanos como la inteligencia artificial son capaces de imaginar y representar objetos y escenas, tanto inexistentes como existentes. Sin embargo, a diferencia de los generadores de imágenes de IA, las imágenes creadas por humanos pueden incluir un contenido muy particular, detalles únicos minúsculos y una estética distintiva que actualmente está fuera del alcance de la IA. En otras palabras, hoy en día, un gran grupo de ilustradores, fotógrafos y diseñadores altamente cualificados y experimentados puede representar todo lo que una red neuronal entrenada puede hacer (aunque llevará mucho más tiempo), pero también pueden crear objetos, composiciones o estéticas que la red neuronal no puede hacer actualmente. Igualmente importante, pueden representar objetos, rostros, composiciones, etc., únicos- a diferencia de las versiones, a menudo más comunes o idealizadas, generadas por la IA.
¿Cuál es la causa de esta brecha estética y de contenido entre los creadores humanos y artificiales? “Los átomos culturales,” estructuras y patrones que aparecen con mayor frecuencia en los datos de entrenamiento se aprenden con gran éxito durante el proceso de entrenamiento de una red neuronal artificial. En la mente de una red neuronal, adquieren mayor importancia. Por otro lado, “los átomos” y estructuras que son poco frecuentes en los datos de entrenamiento o que solo aparecen una vez difíclmente se aprenden o ni siquiera se analizan. No entran en el universo cultural artificial aprendido por la IA. En consecuencia, cuando le pedimos a la IA que los sintetice, no puede hacerlo.
Debido a esto, las IA de texto a imagen como Midjourney, Stable Diffusion o RunwayML no pueden actualmente generar dibujos en mi estilo, ampliarlos añadiendo nuevas partes generadas ni reemplazar partes específicas de mis dibujos con nuevo contenido dibujado en mi estilo (por ejemplo, no pueden realizar un “outpainting” o “inpainting” útil en las fotos digitales de mis dibujos). En cambio, estas herramientas de IA generan objetos más genéricos que los que dibujo habitualmente o producen algo meramente ambiguo y sin interés.
Ciertamente no estoy afirmando que el estilo y el mundo que se muestra en mis dibujos sean completamente únicos. También son el resultado de encuentros culturales específicos que tuve, cosas que observé y cosas que noté. Pero debido a que son poco comunes (y por lo tanto impredecibles), a la IA le resulta difícil simularlos, al menos sin un entrenamiento adicional usando mis dibujos.
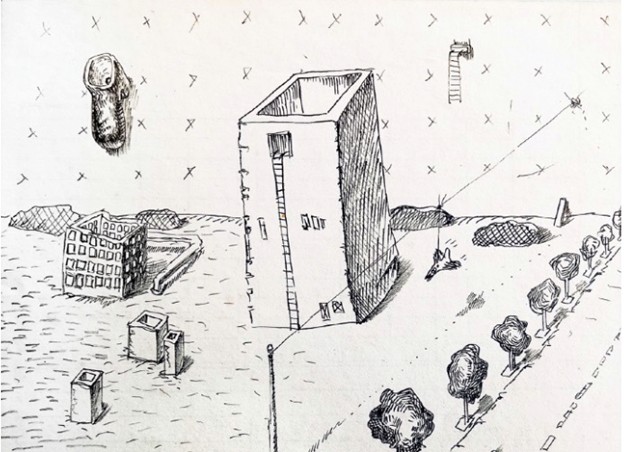
Imagen 6. (Lev Manovich, dibujo sin título, lápiz papel, 1981-1982.)

Imagen 7. (Uno de mis intentos de generar una nueva versión de esta imagen con Stable Diffusion AI, otoño de 2022.)
Aquí nos encontramos con lo que considero el mayor obstáculo al que se enfrentan los creadores al utilizar medios generativos de IA:
La IA genera con frecuencia nuevos artefactos multimedia que son más estereotipados o idealizados de lo que pretendíamos.
Esto puede afectar cualquier dimensión de la imagen: elementos de contenido, iluminación, tramado, atmósfera, estructura espacial y detalles de formas 3D, entre otros. En ocasiones, es evidente de inmediato, en cuyo caso se puede intentar corregirlo o ignorar los resultados. Sin embargo, con frecuencia, estas “sustituciones” son tan sutiles que no podemos detectarlas sin una observación exhaustiva o, en algunos casos, el uso de un ordenador para analizar cuantitativamente numerosas imágenes. En otras palabras, los nuevos modelos de medios generativos de IA, al igual que la disciplina de la estadística desde sus inicios en el siglo XVIII y el campo de la ciencia de datos desde finales de la década de 2010, gestionan bien los elementos y patrones frecuentes en los datos, pero no saben qué hacer con los poco frecuentes y poco comunes. Podemos esperar que los investigadores de IA puedan resolver este problema en el futuro, pero parece tan fundamental que no deberíamos anticipar una solución inmediata.
- Tema y Estilo
En las artes, la relación entre “contenido” y “forma” se ha debatido y teorizado ampliamente. Esta breve sección no pretende abordar todos estos debates ni iniciar debates con todas las teorías relevantes. En cambio, me gustaría considerar cómo estos conceptos se desarrollan en la ‘cultura generativa’ de la IA. Sin embargo, en lugar de utilizar “contenido” y “forma,” utilizaré un par de términos diferentes, más comunes en las publicaciones de investigación sobre IA y en las conversaciones en línea entre usuarios: tema y estilo.
A primera vista, las herramientas multimedia de IA parecen capaces de distinguir claramente entre el tema y el estilo de cualquier representación. En los modelos de texto a imagen, por ejemplo, se pueden generar innumerables imágenes del mismo tema. Añadir los nombres de artistas, medios, materiales y períodos históricos específicos del arte es todo lo que se necesita para que el mismo tema se represente de forma diferente y coincida con estas referencias. Los filtros de Photoshop comenzaron a separar el tema del estilo ya en la década de 1990, pero las herramientas de medios generativos de IA son más eficaces. Por ejemplo, si especifica “pintura al óleo” en su solicitud, las pinceladas simuladas variarán en tamaño y dirección en la imagen generada en los objetos representados. Las herramientas multimedia de IA parecen comprender la semántica de la representación, a diferencia de los filtros anteriores que simplemente aplicaban la misma transformación en cada región de la imagen, independientemente de su contenido. Por ejemplo, al usar “un cuadro de Malevich” y “un cuadro de El Bosco” en la misma consigna, Midjourney generó una imagen del espacio que contenía formas abstractas similares a las de Malevich, así como numerosas pequeñas figuras humanas y animales, como en las populares pinturas de El Bosco, correctamente escaladas para la perspectiva.

Imagen 8. Imagen generada en Midjourney usando el prompt “Cuadro de Malevich y El Bosco,” otoño de 2022.
Las herramientas de IA suelen añadir contenido a una imagen que no especifiqué en mi prompt de texto, además de representar lo que solicité. Esto ocurre con frecuencia cuando la solicitud incluye “al estilo de” o “por” seguido del nombre de un artista visual o fotógrafo de renombre. En un experimento, utilicé la misma solicitud con la herramienta de imagen de IA Midjourney 148 veces, añadiendo cada vez el nombre de un fotógrafo diferente. El tema de la solicitud se mantuvo prácticamente igual: un paisaje vacío con algunos edificios, una carretera y postes eléctricos con cables que se extendían hasta el horizonte. En ocasiones, añadir el nombre de un fotógrafo no afectaba los elementos de la imagen generada que se ajustaban a nuestro concepto intuitivo de estilo, como el contraste, la perspectiva y la atmósfera. Pero, ocasionalmente, Midjourney también modificaba el contenido de la imagen. Por ejemplo, cuando obras conocidas de un fotógrafo en particular presentan figuras humanas en poses específicas, la herramienta añadía ocasionalmente dichas figuras a mis fotografías. (Al igual que Malévich y El Bosco, se transformaron para adaptarse a la composición espacial del paisaje en lugar de duplicarse mecánicamente). Midjourney también ha modificado en ocasiones el contenido de mi imagen para que coincida con un período histórico en el que un fotógrafo reconocido creó sus fotografías más famosas.
Según mis observaciones, cuando le pedimos a Midjourney o a una herramienta similar que cree una imagen al estilo de un artista específico, y el tema que describimos en la propuesta se relaciona con los temas típicos del artista, los resultados pueden ser muy satisfactorios. Sin embargo, cuando el tema de nuestra propuesta y las imágenes de este artista son muy diferentes, la representación del tema en este estilo suele fracasar.
Utilizando el prompt “por Caspar David Friedrich –v 5” en Midjourney genera imágenes que capturan a la perfección el estilo del artista. Fuente: https://www.midlibrary.io/styles/caspar-david-friedrich.

Imagen 9.
Utilizando el prompt “Peonías en descomposición de Caspar David Friedrich” en Midjourney genera imágenes que simulan características importantes del estilo del artista, como combinaciones de colores fríos y una atmósfera dramática. Sin embargo, en otros aspectos, las imágenes generadas se alejan significativamente del estilo del artista. Los tipos de líneas, la representación de los detalles y las composiciones simétricas de estas imágenes de IA nunca aparecerían en las pinturas reales de Friedrich. La IA también puede insertar objetos de aspecto genérico, como las formaciones rocosas en la esquina superior derecha de la primera imagen.


En resumen, para simular con éxito un estilo visual determinado con las herramientas actuales de IA, es posible que sea necesario modificar el contenido que se pretendía representar. No todos los temas se pueden representar de forma satisfactoria en cualquier estilo. Además, la IA suele aprender con éxito algunas características del estilo del artista, pero no otras.
Creo que estas observaciones complican la oposición binaria entre los conceptos de “contenido” y “estilo.” Para algunos artistas, la IA puede extraer al menos algunos aspectos del estilo de ejemplos de su obra y luego aplicarlos a diferentes tipos de contenido. Pero para otros, al parecer, su estilo y su contenido son inseparables. (Esta es solo mi observación inicial, que se desarrollará más a fondo tras realizar más experimentos en Midjourney).
Para mí, este tipo de observaciones y reflexiones son una de las razones más importantes para utilizar nuevas tecnologías mediáticas, como los medios generativos de IA, y aprender cómo funcionan. Por supuesto, como artista practicante y teórico del arte, he estado pensando en las relaciones entre tema y estilo (o contenido y forma) durante mucho tiempo, pero ser capaz de llevar a cabo experimentos sistemáticos como el que describí aporta nuevas ideas y nos permite mirar atrás en la historia cultural y al arte de nuevas maneras.
Notas
[1]Nota de la traductora: El texto original en inglés intitulado “Seven Arguments about AI Images and Generative Media” es el capítulo 5 del libro Lev Manovich y Emanuele Arielli, Artifical Aesthetics (2024.) Véase:
https://manovich.net/index.php/projects/artificial-aesthetics. Agradezco a Lev Manovich por haberme enviado el original y otorgarme el derecho de publicar su traducción en español aquí. Comunicación con el autor por vía electronica el 22 de agosto de 2025.
[2] Nota del autor: “Una versión preliminar de una parte de este capítulo se publicará en Diffusions – Taxonomy of Synthetic Imaginations in Architecture, ed. Matias del Campo (Willey, 2023;) y una versión preliminar más corta de otra parte se publicará en https://www.moma.org/magazine, 2023. Este capítulo fue escrito por mí sin utilizar herramientas de escritura de IA. Durante la edición, utilicé la herramienta https://quillbot.com, que ofrece versiones parafraseadas de las frases seleccionadas.”